Indexar es la acción de construir un fichero inverso de forma automática ó manual. Este proceso es necesario para localizar y recuperar rápidamente cada uno de los términos del texto de un documento. Esto significa que a cada palabra se le asigna un identificador del documento en el que aparece, un indicador de la posición que ocupa en el texto (párrafo, línea, número de caracter de inicio) y un número de identificación para ese término propiamente dicho (único e irrepetible). De esta forma se conoce la posición exacta de cada término en los documentos de la colección y posibilita el posterior análisis de frecuencias.
Para llevar a cabo la indexación, tal como apunta Baeza Yates, se requiere de una importante capacidad de computación y por ende existe gran dependencia de las prestaciones del hardware para llevarlo a cabo. Si el corpus documental es la propia red WWW, se necesitará un motor de indexación distribuida. Eso significa que existen decenas de equipos informáticos (servidores), trabajando con una agrupación de contenidos determinada, colaborando en común para generar un gran índice que será utilizado a la postre por el motor de búsqueda. La indexación, también deberá ser dinámica. Esta propiedad significa que ante un corpus cambiante como puede ser la web, se necesitan reindexaciones continuas de los contenidos y por ende su modificación y ampliación.
Para llevar a cabo la indexación, tal como apunta Baeza Yates, se requiere de una importante capacidad de computación y por ende existe gran dependencia de las prestaciones del hardware para llevarlo a cabo. Si el corpus documental es la propia red WWW, se necesitará un motor de indexación distribuida. Eso significa que existen decenas de equipos informáticos (servidores), trabajando con una agrupación de contenidos determinada, colaborando en común para generar un gran índice que será utilizado a la postre por el motor de búsqueda. La indexación, también deberá ser dinámica. Esta propiedad significa que ante un corpus cambiante como puede ser la web, se necesitan reindexaciones continuas de los contenidos y por ende su modificación y ampliación.
Todo ello justifica que junto al proceso de indexación, se trate de reducir al máximo el tamaño de tales archivos o tablas de la base de datos para conseguir la mejor relación entre tiempo de ejecución de las consultas y exhaustividad del fichero inverso. A esta misión se la denomina "compresión de la indexación" y en ella se circunscriben los procesos de depuración que se han mostrado en el artículo anterior, tales como la supresión de palabras vacías, la normalización de palabras, la transliteración de caracteres especiales y la reducción morfológica o "stemming" que se abordará en este capítulo.
La compresión de la indexación
- Depuración de los textos de los documentos de la colección
- Supresión de palabras vacías (primer filtro)
- Reducción morfológica
- Stemming
- Lematización
- Supresión de palabras vacías (segundo filtro)
- La ley de Zipf y la frecuencia de aparición
- Técnica de cortes de Luhn: Cut-on y Cut-off
- Cálculo del punto de transición
Reducción morfológica
La reducción morfológica es el proceso por el cual se depuran todos los términos de un texto, reduciendo su número de caracteres, simplificando su forma original, género, número, desinencia, prefijo, sufijo en una forma de palabra más común o normalizada, debido a que la mayor parte de ellas tienen la misma significación semántica. Este proceso reduce el tamaño de los términos, del diccionario, fichero inverso y mejora el "recall" o exhaustividad de los resultados en la recuperación de información.
Stemming
Efectúa una reducción de las palabras a sus elementos mínimos con significado, las raíces de las palabra, de hecho "Stem" significa tallo ó raíz. De esta forma, los procesos de stemming, acotan las terminaciones de las palabras a su forma más genérica o común, obsérvese la tabla1.
Término
|
Stem
|
Término
|
Stem
| |
che
|
che
|
consign
|
consign
| |
checa
|
chec
|
consigned
|
consign
| |
checar
|
chec
|
consigning
|
consign
| |
checo
|
chec
|
consignment
|
consign
| |
checoslovaquia
|
checoslovaqui
|
consist
|
consist
| |
chedraoui
|
chedraoui
|
consisted
|
consist
| |
chefs
|
chefs
|
consistency
|
consist
| |
cheliabinsk
|
cheliabinsk
|
consistent
|
consist
| |
chelo
|
chel
|
consistently
|
consist
| |
chemical
|
chemical
|
consisting
|
consist
| |
chemicalweek
|
chemicalweek
|
consists
|
consist
| |
chemise
|
chemis
|
consolation
|
consol
| |
chepo
|
chep
|
consolations
|
consol
| |
cheque
|
chequ
|
consolatory
|
consolatori
| |
chequeo
|
cheque
|
console
|
consol
| |
cheques
|
chequ
|
consoled
|
consol
| |
cheraw
|
cheraw
|
consoles
|
consol
| |
chesca
|
chesc
|
consolidate
|
consolid
| |
chester
|
chest
|
consolidated
|
consolid
| |
chetumal
|
chetumal
|
consolidating
|
consolid
| |
chetumaleños
|
chetumaleñ
|
consoling
|
consol
| |
chevrolet
|
chevrolet
|
consolingly
|
consol
| |
cheyene
|
cheyen
|
consols
|
consol
| |
cheyenne
|
cheyenn
|
consonant
|
conson
| |
chi
|
chi
|
consort
|
consort
| |
chía
|
chi
|
consorted
|
consort
| |
chiapaneca
|
chiapanec
|
consorting
|
consort
| |
chiapas
|
chiap
|
conspicuous
|
conspicu
| |
chiba
|
chib
|
conspicuously
|
conspicu
| |
chic
|
chic
|
conspiracy
|
conspiraci
| |
chica
|
chic
|
conspirator
|
conspir
| |
chicago
|
chicag
|
conspirators
|
conspir
| |
chicana
|
chican
|
conspire
|
conspir
| |
chicano
|
chican
|
conspired
|
conspir
| |
chicas
|
chic
|
conspiring
|
conspir
| |
chicharrones
|
chicharron
|
constable
|
constabl
| |
chichen
|
chich
|
constables
|
constabl
| |
chichimecas
|
chichimec
|
constance
|
constanc
| |
chicles
|
chicl
|
constancy
|
constanc
| |
chico
|
chic
|
constant
|
constant
| |
Fuente: Proyecto Snowball. Disponible en: http://snowball.tartarus.org/
| ||||
Tabla1. Ejemplo clásico de stemming
Como se desprende del análisis de los ejemplos de la tabla1, tanto en inglés como en español y en cualquier idioma, un término puede ser reducido a su común denominador, permitiendo la recuperación de todos los documentos cuyas palabras tengan la misma raíz común, por ejemplo (catálogo, catálogos, catalogación, catalogador, catalogar, catalogando, catalogado, catalogándonos). Todos los términos derivan en tal caso de "catalog", haciendo posible que la recuperación sea completa en más de 8 supuestos distintos. No obstante no siempre esta técnica permite funcionar perfectamente todas las consultas que un usuario pueda plantear, es el caso de eliminar prefijos y sufijos cuya raíz puede ser compartida por múltiples palabras, véase tabla2.
Término con prefijo
|
Raíz/Stem
|
Término con el que causaría confusión
|
Prevalencia
|
valenc
|
Valencia, valencia, valenciano, ambivalencia, polivalencia,
|
Precatalogar
|
catalog
|
Descatalogar, catalogo,
|
Tabla2. Ejemplo de conflictos de los procesos de stemming
Uno de los métodos más conocidos para llevar a efecto la reducción morfológica es el algoritmo de Martin Porter, diseñado para eliminar las palabras más comunes del inglés inicialmente y posteriormente aplicado para terceros idiomas, véase bibliografía de Porter y proyecto Snowball.
La ley de Zip y la frecuencia de aparición
En 1949 el lingüista y científico George Kingsley Zipf, formuló la ley empírica (de tipo potencial) que lleva su nombre y con la que se determina que la frecuencia de cualquier palabra es inversamente proporcional a la posición que ocupa en la tabla de frecuencias. Esto significa que la palabra más frecuente de un texto tiene una frecuencia de aparición que dobla a la de la segunda palabra más frecuente. La segunda palabra más frecuente tendrá una frecuencia de aparación que dobla a la de la tercera palabra más frecuente. Dicho de otra forma, la frecuencia de aparición de una palabra es inversamente proporcional a su número de orden. Y de esta forma se repetiría el esquema potencial de la ley Zipf con todos los términos del texto, véase la tabla3 donde se demuestra este concepto.
t
|
(n)
|
tf(n)
|
K = tf(n) x (n)
Constante ZIPF
|
Ley de ZIPF
tf(n) = K/(n)
|
Término, palabra.
|
Rango o posición de las palabras en el ranking.
|
Frecuencia de aparición de un término.
|
La constante de Zipf es igual a la frecuencia de aparición del término por su rango.
|
La frecuencia de aparición de un término es igual a la constante de Zipf dividida por el rango de la palabra.
|
de
|
1
|
85234
|
85234
|
85234 / 1
|
a
|
2
|
42617
|
85234
|
85234 / 2
|
el
|
3
|
28411
|
85233
|
85234 / 3
|
un
|
4
|
21308
|
85232
|
85234 / 4
|
los
|
5
|
17046
|
85230
|
85234 / 5
|
las
|
6
|
14205
|
85230
|
85234 / 6
|
que
|
7
|
12176
|
85232
|
85234 / 7
|
Tabla3. Ejemplo de la ley Zipf
Abundando en lo expresado en la tabla1, se observa que la ley de Zipf determina que la frecuencia de aparición de un término es inversamente proporcional a su número de rango (orden o posición que ocupa entre las palabras más frecuentes) de tal manera que se puede preveer cual será aproximadamente su valor empleando la siguiente formulación, véase figura1.
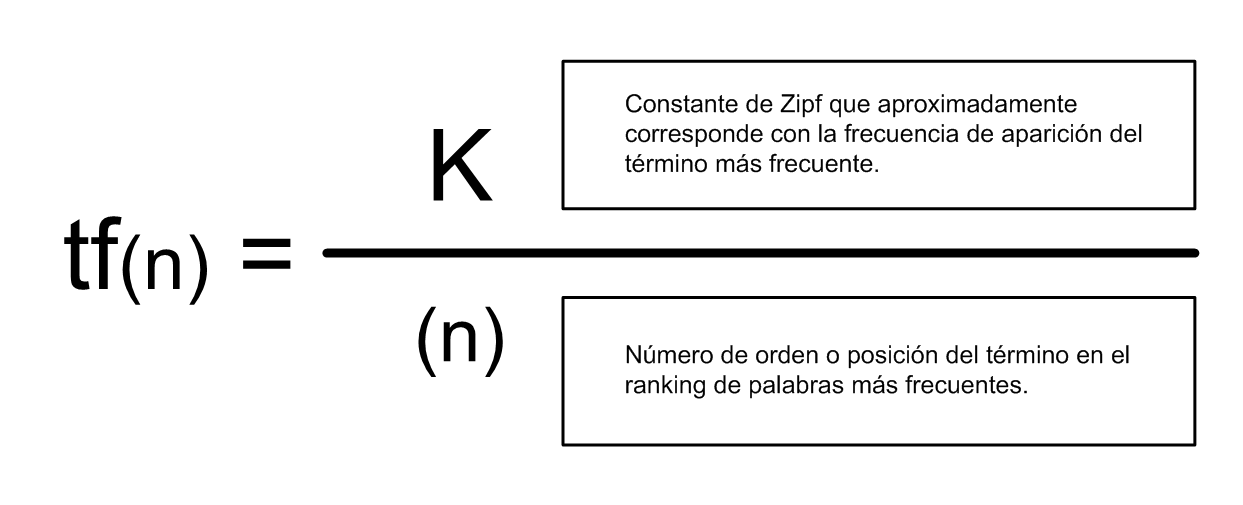
Figura1. Fórmula de ley de Zipf
Como se observará, al ser una ley empírica, cuando se calcula la constante K para todos los términos del ranking, no siempre el valor es coincidente con la frecuencia de aparición de tf(1). No obstante, este valor es aproximado y permite determinar en qué medida se cumple la ley de Zipf y cuál es la desviación por error. Basándose en estas formulaciones, Zipf descubre que en efecto las palabras más frecuentes, cerca del 75% del total, correspondían a palabras de mínima representatividad y que aproximadamente entre el 20% y el 30% de las palabras de un documento eran las realmente significativas y susceptibles de recuperación, véase figura2.
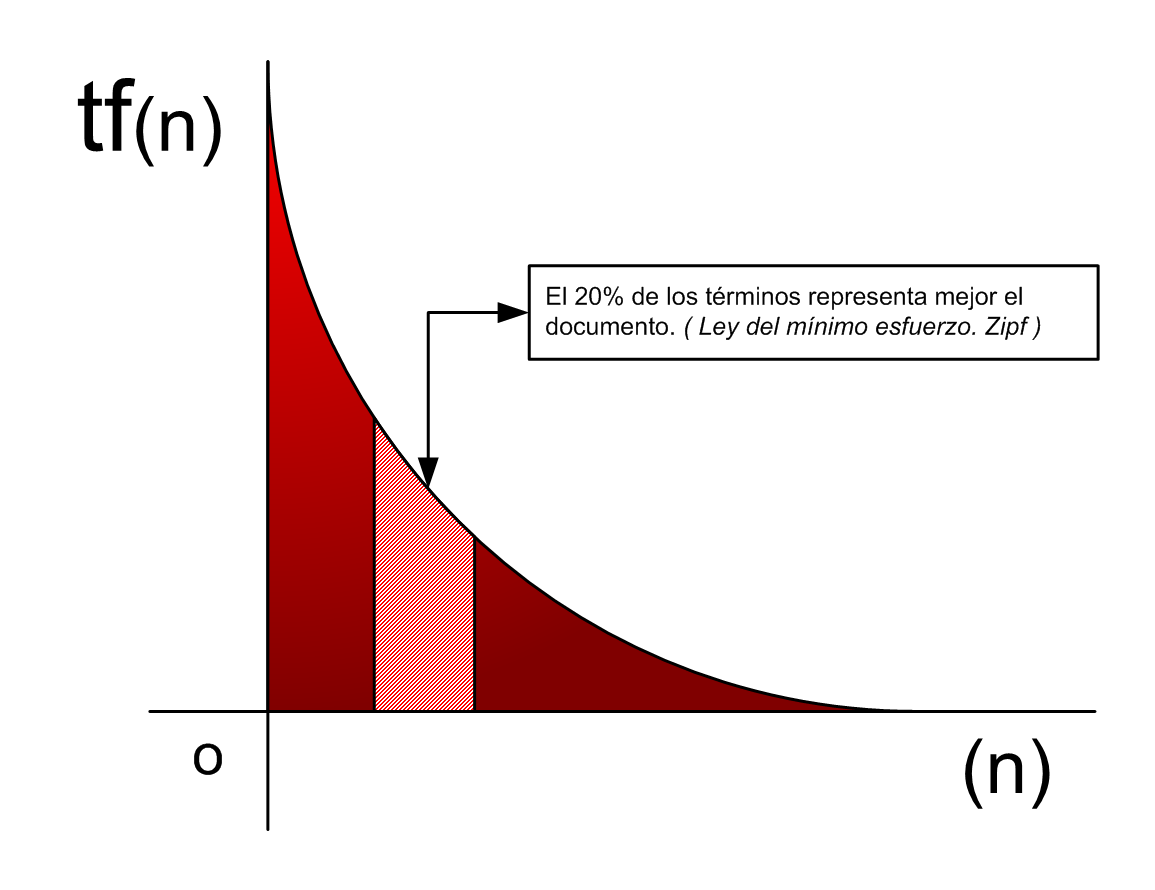
Figura2. Función logarítmica de la frecuencia de los términos de un documento
Llega a esta conclusión basándose en la ley del mínimo esfuerzo, ya que se supone que el usuario no utilizará términos de búsqueda cuya frecuencia de aparición sea tan baja o tan elevada como para encontrarse en los bordes potenciales del cuadro logarítmico, prefiriendo utilizar por consiguiente un término más común ó habitual con una frecuencia de aparición media.
Técnica de cortes de Luhn: Cut-on y Cut-off
Según lo especificado en la figura2, la expresión logarítmica de los términos de un documento, muestra una curva pronunciada con los términos de altísima frecuencia de aparición y su inverso, aquellos términos de muy baja frecuencia de aparición. Este hecho, ya adelantado por Zipf, dió lugar al empleo de la técnica de cortes que propuso Luhn en 1958, conjetura por la que ya se venía intuyendo que los términos situados en los extremos del eje de abscisas y de ordenadas serán los que menos poder de resolución o representatividad tienen para un determinado documento dentro de la colección. Consiste en la eliminación de los términos de altísima frecuencia de aparición (Cut-on) y términos de bajísima frecuencia de aparición (Cut-off), entre los que se incluyen los "Hápax", términos cuya frecuencia de aparición es la unidad. Véanse las figura3, 4 y 5 basadas en (SCHULTZ, C.K. 1968).



La cuestión a plantear en este punto sería ¿cómo se aplicaban los cortes? ¿cómo se determinaba que los términos de una frecuencia de aparición determinada eran merecedores o no de supresión y eliminación, previos a la indexación? Inicialmente la técnica de cortes propuesta por Luhn se realizaba de forma arbitraria, eliminando un porcentaje de términos alineados en los extremos del ranking.
Cálculo del punto de transición
Para averiguar de forma científica la estimación del corte superior "Cut-on" e inferior "Cut-off", una de las soluciones más estudiadas es el cálculo del punto de transición o inflexión entre los términos generales y especializados, cuyas características pueden resumirse en la tabla4.
Teniendo claras estas circunstancias y sabiendo que en los términos con frecuencias medias están los términos representativos; el investigador Andrew Donald Booth (BOOTH, A.D. 1967), perfecciona la técnica del punto de transición de William Goffman (URBIZAGÁSTEGUI ALVARADO, R.; RESTREPO ARANGO, C. 2011), en su trabajo titulado A Law of Occurrences for Words of Low Frequency, donde diseña una formulación refinada, véase figura6.

El punto de transición no es más que una frecuencia de aparición intermedia a partir de la cual, se determina el porcentaje de términos tendientes a la generalidad o a la especificidad (según se separen de la frecuencia de aparición del punto de transición) para determinar dónde efectuar los cortes. Véase figura7.

Pero aún estableciendo un punto de transición, aún faltan por determinar los puntos de corte Cut-on y Cut-off, esto se lleva a cabo mediante 2 rangos definidos o bien mediante porcentajes o por valores aproximados a la frecuencia del punto de corte. Tales rangos no tienen porque resultar simétricos, dependiendo del tipo de recuperación que se pretenda conseguir a la postre. Una recuperación más precisa, deberá incluir más términos con frecuencias de aparición bajas. Si se desea una recuperación más exhaustiva, se deberá primar un margen superior para el Cut-on. Obsérvese en la figura7, que tales rangos se definen a partir del valor de la frecuencia de aparición del punto de corte, tanto a derecha como a izquierda, haciendo que el segmento resultante sea el conjunto definitivo a tener en cuenta en la indexación.
Según lo especificado en la figura2, la expresión logarítmica de los términos de un documento, muestra una curva pronunciada con los términos de altísima frecuencia de aparición y su inverso, aquellos términos de muy baja frecuencia de aparición. Este hecho, ya adelantado por Zipf, dió lugar al empleo de la técnica de cortes que propuso Luhn en 1958, conjetura por la que ya se venía intuyendo que los términos situados en los extremos del eje de abscisas y de ordenadas serán los que menos poder de resolución o representatividad tienen para un determinado documento dentro de la colección. Consiste en la eliminación de los términos de altísima frecuencia de aparición (Cut-on) y términos de bajísima frecuencia de aparición (Cut-off), entre los que se incluyen los "Hápax", términos cuya frecuencia de aparición es la unidad. Véanse las figura3, 4 y 5 basadas en (SCHULTZ, C.K. 1968).

Figura3. Los cortes de Luhn Cut-on, Cut-off y los términos significativos con frecuencias medias

Figura4. En color rojo, la curva hiperbólica que representa el área de términos con capacidad de resolución y representación del documento
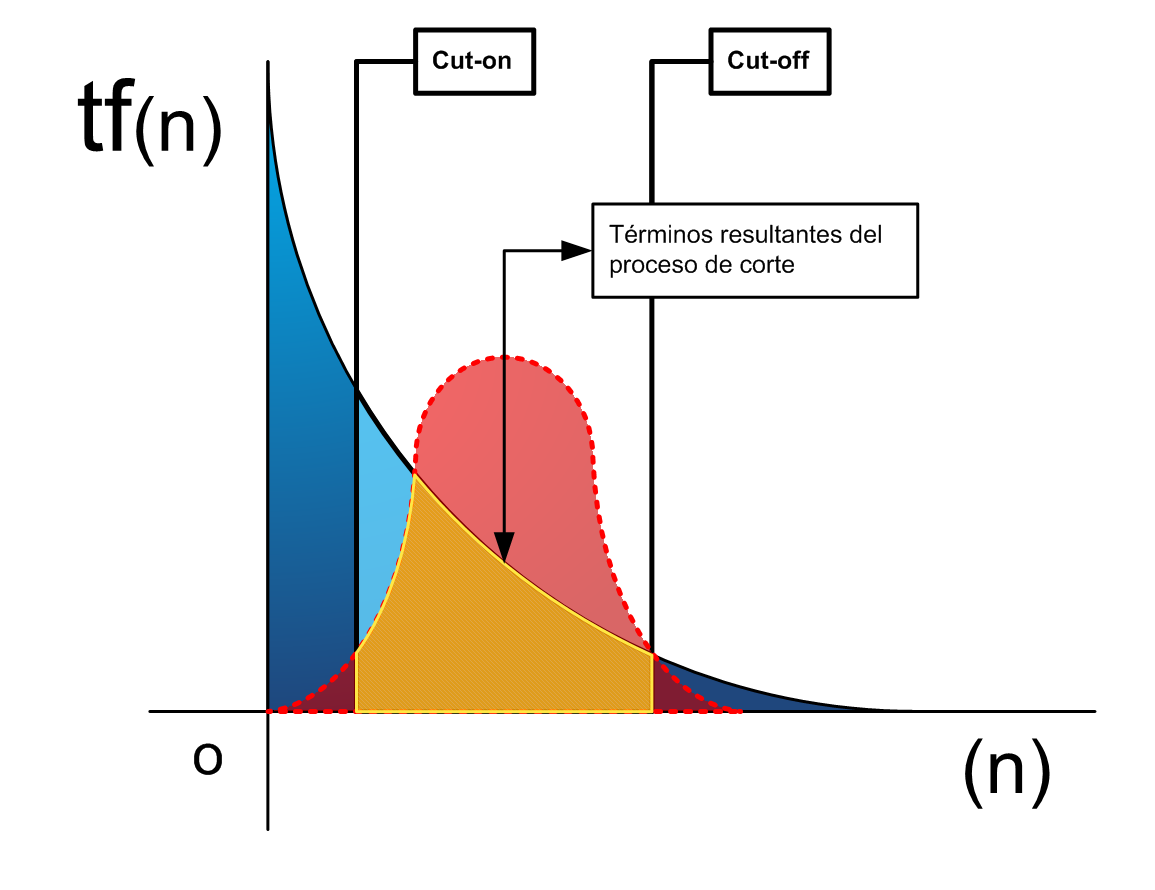
Figura5. El área amarilla representa los términos significativos y resolutivos resultante del proceso de corte y de la curva hiperbólica.
La cuestión a plantear en este punto sería ¿cómo se aplicaban los cortes? ¿cómo se determinaba que los términos de una frecuencia de aparición determinada eran merecedores o no de supresión y eliminación, previos a la indexación? Inicialmente la técnica de cortes propuesta por Luhn se realizaba de forma arbitraria, eliminando un porcentaje de términos alineados en los extremos del ranking.
Cálculo del punto de transición
Para averiguar de forma científica la estimación del corte superior "Cut-on" e inferior "Cut-off", una de las soluciones más estudiadas es el cálculo del punto de transición o inflexión entre los términos generales y especializados, cuyas características pueden resumirse en la tabla4.
Términos con
alta frecuencia de aparición
|
Términos con
baja frecuencia de aparición
|
Generales
|
Específicos
|
Tienden a unificar el lenguaje
|
Tienden a diversificar el lenguaje
|
Proporcionan nexos de unión en torno al texto
|
Detallan el contenido del texto
|
Pulsión
|
Repulsión
|
Artículos, preposiciones, conjunciones, contracciones, pronombres, algunos adverbios y verbos
|
Terminología especializada de un determinado área de conocimiento, vocabulario técnico, científico, Hápax
|
Rangos cercanos al origen del eje
|
Rangos situados en el extremo opuesto al origen
|
Técnica de recorte aplicada: Cut-on
|
Técnica de recorte aplicada: Cut-off
|
Tabla4. Características de los términos según su frecuencia
Teniendo claras estas circunstancias y sabiendo que en los términos con frecuencias medias están los términos representativos; el investigador Andrew Donald Booth (BOOTH, A.D. 1967), perfecciona la técnica del punto de transición de William Goffman (URBIZAGÁSTEGUI ALVARADO, R.; RESTREPO ARANGO, C. 2011), en su trabajo titulado A Law of Occurrences for Words of Low Frequency, donde diseña una formulación refinada, véase figura6.
Figura6. Fórmula de Booth para el cálculo del punto de transición.
El punto de transición no es más que una frecuencia de aparición intermedia a partir de la cual, se determina el porcentaje de términos tendientes a la generalidad o a la especificidad (según se separen de la frecuencia de aparición del punto de transición) para determinar dónde efectuar los cortes. Véase figura7.
Figura7. Representación del punto de transición
Pero aún estableciendo un punto de transición, aún faltan por determinar los puntos de corte Cut-on y Cut-off, esto se lleva a cabo mediante 2 rangos definidos o bien mediante porcentajes o por valores aproximados a la frecuencia del punto de corte. Tales rangos no tienen porque resultar simétricos, dependiendo del tipo de recuperación que se pretenda conseguir a la postre. Una recuperación más precisa, deberá incluir más términos con frecuencias de aparición bajas. Si se desea una recuperación más exhaustiva, se deberá primar un margen superior para el Cut-on. Obsérvese en la figura7, que tales rangos se definen a partir del valor de la frecuencia de aparición del punto de corte, tanto a derecha como a izquierda, haciendo que el segmento resultante sea el conjunto definitivo a tener en cuenta en la indexación.
Bibliografía
BAEZA YATES, R.; RIBEIRO-NETO, B. 1999. Modern Information Retrieval. Addison Wesley.
BERRY, M.W.; BROWNE, M. 2005. Understanding Search Engines: Mathematical modeling and text retrieval. Siam.
BOOTH, A. D. 1967. A Law of Occurrences for Words of Low Frequency. Information and control, 10(4):386-393. Disponible en: http://www.sciencedirect.com/science/article/pii/S001999586790201X
JIMÉNEZ SALAZAR, H.; PINTO, D.; ROSSO, P. 2005. Uso del punto de transición en la selección de términos índice para agrupamiento de textos cortos. En: Procesamiento del Lenguaje Natural. 35: pp. 383-390. Disponible en: http://www.sepln.org/revistaSEPLN/revista/35/47.pdf
LUHN, H. P. 1958. The Automatic Creation of Literature Abstracts. IBM Journal of Research Development, 2(2): pp.159-165
MANNING, C.D.; RAGHAVAN, P.; SCHÜTZE, H. 2008. Introduction to Information Retrieval. Cambridge University Press
PORTER, M.F. 1980, An algorithm for suffix stripping, Program, 14(3) pp 130−137.
PORTER, M.F. 2006. The Porter Stemming Algorithm. Disponible en: http://tartarus.org/~martin/PorterStemmer/
PORTER, M.F.; BOULTON, R. 2010. Snowball. Disponible en: http://snowball.tartarus.org/
RIJSBERGEN, C.J.; [et.al.] 1979. Information Retrieval. Disponible en: http://www.dcs.gla.ac.uk/Keith/Chapter.2/Ch.2.html
RIJSBERGEN, C.J.; Robertson S.E.; PORTER, M.F. 1980. New models in probabilistic information retrieval. London: British Library. (British Library Research and Development Report, no. 5587).
SCHULTZ, C.K. 1968. H.P. Luhn: Pioneer of Information Science - Selected Works. Macmillan.
SEEGER, M. 2010. Building blocks of a scalable web crawler. Department of Computer Science and Media, Stuttgart University. Disponible en: http://blog.marc-seeger.de/assets/papers/thesis_seeger-building_blocks_of_a_scalable_webcrawler.pdf
SPARCK JONES, K.; WILLET, P. 1997. Readings in Information Retrieval, San Francisco: Morgan Kaufmann.
URBIZAGÁSTEGUI ALVARADO, R. 1999. Las posibilidades de la ley de zipf en la indización automática. En: B3 Bibliotecología, Bibliotecas, Bibliotecólogos. Disponible en: http://b3.bibliotecologia.cl/ruben2.htm
URBIZAGÁSTEGUI ALVARADO, R.; RESTREPO ARANGO, C. 2011. La ley de Zipf y el punto de transición de Goffman en la indización automática. En: Investigación Bibliotecológica. 25(54): pp. 71-92. Disponible en: http://www.journals.unam.mx/index.php/ibi/article/download/27482/25470
VELASCO, I.; DÍAZ, J.; LLORÉNS, A. 1999. Algoritmo de filtrado multi-término para la obtención de relaciones jerárquicas en la construcción automática de un tesauro. En: Revista Española de Documentación Científica, 22(1): pp. 34-49 Disponible en: http://redc.revistas.csic.es/index.php/redc/article/view/333/542
ZIPF, G. K. 1949. Human behaviour and the principle of least effort. Addison-Wesley.
La información es impecable. Muchas gracias por compartir esto. Por cierto, dígame por favor: ¿cuál es el software que utiliza para generar sus ilustraciones y gráficas?
ResponderEliminarEnhorabuena, ya hacia falta algo así en el idioma español.
Muchas gracias por seguir este blog, me alegro de que te guste y valores su contenido. En cuanto al software que empleo para elaborar las ilustraciones es Microsoft Visio, cada ilustración e imagen la diseñé expresamente para cada artículo.
ResponderEliminarUn abrazo desde España